Reading and writing files¶
xarray supports direct serialization and IO to several file formats, from simple Pickle files to the more flexible netCDF format (recommended).
netCDF¶
The recommended way to store xarray data structures is netCDF, which
is a binary file format for self-described datasets that originated
in the geosciences. xarray is based on the netCDF data model, so netCDF files
on disk directly correspond to Dataset objects (more accurately,
a group in a netCDF file directly corresponds to a to Dataset object.
See Groups for more.)
NetCDF is supported on almost all platforms, and parsers exist for the vast majority of scientific programming languages. Recent versions of netCDF are based on the even more widely used HDF5 file-format.
Tip
If you aren’t familiar with this data format, the netCDF FAQ is a good place to start.
Reading and writing netCDF files with xarray requires scipy or the netCDF4-Python library to be installed (the later is required to read/write netCDF V4 files and use the compression options described below).
We can save a Dataset to disk using the
Dataset.to_netcdf() method:
In [1]: ds = xr.Dataset(
...: {"foo": (("x", "y"), np.random.rand(4, 5))},
...: coords={
...: "x": [10, 20, 30, 40],
...: "y": pd.date_range("2000-01-01", periods=5),
...: "z": ("x", list("abcd")),
...: },
...: )
...:
In [2]: ds.to_netcdf("saved_on_disk.nc")
By default, the file is saved as netCDF4 (assuming netCDF4-Python is
installed). You can control the format and engine used to write the file with
the format and engine arguments.
Tip
Using the h5netcdf package
by passing engine='h5netcdf' to open_dataset() can
sometimes be quicker than the default engine='netcdf4' that uses the
netCDF4 package.
We can load netCDF files to create a new Dataset using
open_dataset():
In [3]: ds_disk = xr.open_dataset("saved_on_disk.nc")
In [4]: ds_disk
Out[4]:
<xarray.Dataset>
Dimensions: (x: 4, y: 5)
Coordinates:
* x (x) int64 10 20 30 40
* y (y) datetime64[ns] 2000-01-01 2000-01-02 ... 2000-01-04 2000-01-05
z (x) object ...
Data variables:
foo (x, y) float64 ...
Similarly, a DataArray can be saved to disk using the
DataArray.to_netcdf() method, and loaded
from disk using the open_dataarray() function. As netCDF files
correspond to Dataset objects, these functions internally
convert the DataArray to a Dataset before saving, and then convert back
when loading, ensuring that the DataArray that is loaded is always exactly
the same as the one that was saved.
A dataset can also be loaded or written to a specific group within a netCDF
file. To load from a group, pass a group keyword argument to the
open_dataset function. The group can be specified as a path-like
string, e.g., to access subgroup ‘bar’ within group ‘foo’ pass
‘/foo/bar’ as the group argument. When writing multiple groups in one file,
pass mode='a' to to_netcdf to ensure that each call does not delete the
file.
Data is always loaded lazily from netCDF files. You can manipulate, slice and subset Dataset and DataArray objects, and no array values are loaded into memory until you try to perform some sort of actual computation. For an example of how these lazy arrays work, see the OPeNDAP section below.
It is important to note that when you modify values of a Dataset, even one linked to files on disk, only the in-memory copy you are manipulating in xarray is modified: the original file on disk is never touched.
Tip
xarray’s lazy loading of remote or on-disk datasets is often but not always
desirable. Before performing computationally intense operations, it is
often a good idea to load a Dataset (or DataArray) entirely into memory by
invoking the Dataset.load() method.
Datasets have a Dataset.close() method to close the associated
netCDF file. However, it’s often cleaner to use a with statement:
# this automatically closes the dataset after use
In [5]: with xr.open_dataset("saved_on_disk.nc") as ds:
...: print(ds.keys())
...:
KeysView(<xarray.Dataset>
Dimensions: (x: 4, y: 5)
Coordinates:
* x (x) int64 10 20 30 40
* y (y) datetime64[ns] 2000-01-01 2000-01-02 ... 2000-01-04 2000-01-05
z (x) object ...
Data variables:
foo (x, y) float64 ...)
Although xarray provides reasonable support for incremental reads of files on disk, it does not support incremental writes, which can be a useful strategy for dealing with datasets too big to fit into memory. Instead, xarray integrates with dask.array (see Parallel computing with Dask), which provides a fully featured engine for streaming computation.
It is possible to append or overwrite netCDF variables using the mode='a'
argument. When using this option, all variables in the dataset will be written
to the original netCDF file, regardless if they exist in the original dataset.
Groups¶
NetCDF groups are not supported as part of the Dataset data model.
Instead, groups can be loaded individually as Dataset objects.
To do so, pass a group keyword argument to the
open_dataset() function. The group can be specified as a path-like
string, e.g., to access subgroup 'bar' within group 'foo' pass
'/foo/bar' as the group argument.
In a similar way, the group keyword argument can be given to the
Dataset.to_netcdf() method to write to a group
in a netCDF file.
When writing multiple groups in one file, pass mode='a' to
Dataset.to_netcdf() to ensure that each call does not delete the file.
Reading encoded data¶
NetCDF files follow some conventions for encoding datetime arrays (as numbers
with a “units” attribute) and for packing and unpacking data (as
described by the “scale_factor” and “add_offset” attributes). If the argument
decode_cf=True (default) is given to open_dataset(), xarray will attempt
to automatically decode the values in the netCDF objects according to
CF conventions. Sometimes this will fail, for example, if a variable
has an invalid “units” or “calendar” attribute. For these cases, you can
turn this decoding off manually.
You can view this encoding information (among others) in the
DataArray.encoding and
DataArray.encoding attributes:
In [6]: ds_disk["y"].encoding
Out[6]:
{'zlib': False,
'shuffle': False,
'complevel': 0,
'fletcher32': False,
'contiguous': True,
'chunksizes': None,
'source': 'saved_on_disk.nc',
'original_shape': (5,),
'dtype': dtype('int64'),
'units': 'days since 2000-01-01 00:00:00',
'calendar': 'proleptic_gregorian'}
In [7]: ds_disk.encoding
Out[7]:
{'unlimited_dims': set(),
'source': 'saved_on_disk.nc'}
Note that all operations that manipulate variables other than indexing will remove encoding information.
Reading multi-file datasets¶
NetCDF files are often encountered in collections, e.g., with different files
corresponding to different model runs or one file per timestamp.
xarray can straightforwardly combine such files into a single Dataset by making use of
concat(), merge(), combine_nested() and
combine_by_coords(). For details on the difference between these
functions see Combining data.
Xarray includes support for manipulating datasets that don’t fit into memory
with dask. If you have dask installed, you can open multiple files
simultaneously in parallel using open_mfdataset():
xr.open_mfdataset('my/files/*.nc', parallel=True)
This function automatically concatenates and merges multiple files into a
single xarray dataset.
It is the recommended way to open multiple files with xarray.
For more details on parallel reading, see Combining along multiple dimensions, Reading and writing data and a
blog post by Stephan Hoyer.
open_mfdataset() takes many kwargs that allow you to
control its behaviour (for e.g. parallel, combine, compat, join, concat_dim).
See its docstring for more details.
Note
A common use-case involves a dataset distributed across a large number of files with
each file containing a large number of variables. Commonly a few of these variables
need to be concatenated along a dimension (say "time"), while the rest are equal
across the datasets (ignoring floating point differences). The following command
with suitable modifications (such as parallel=True) works well with such datasets:
xr.open_mfdataset('my/files/*.nc', concat_dim="time",
data_vars='minimal', coords='minimal', compat='override')
This command concatenates variables along the "time" dimension, but only those that
already contain the "time" dimension (data_vars='minimal', coords='minimal').
Variables that lack the "time" dimension are taken from the first dataset
(compat='override').
Sometimes multi-file datasets are not conveniently organized for easy use of open_mfdataset().
One can use the preprocess argument to provide a function that takes a dataset
and returns a modified Dataset.
open_mfdataset() will call preprocess on every dataset
(corresponding to each file) prior to combining them.
If open_mfdataset() does not meet your needs, other approaches are possible.
The general pattern for parallel reading of multiple files
using dask, modifying those datasets and then combining into a single Dataset is:
def modify(ds):
# modify ds here
return ds
# this is basically what open_mfdataset does
open_kwargs = dict(decode_cf=True, decode_times=False)
open_tasks = [dask.delayed(xr.open_dataset)(f, **open_kwargs) for f in file_names]
tasks = [dask.delayed(modify)(task) for task in open_tasks]
datasets = dask.compute(tasks) # get a list of xarray.Datasets
combined = xr.combine_nested(datasets) # or some combination of concat, merge
As an example, here’s how we could approximate MFDataset from the netCDF4
library:
from glob import glob
import xarray as xr
def read_netcdfs(files, dim):
# glob expands paths with * to a list of files, like the unix shell
paths = sorted(glob(files))
datasets = [xr.open_dataset(p) for p in paths]
combined = xr.concat(datasets, dim)
return combined
combined = read_netcdfs('/all/my/files/*.nc', dim='time')
This function will work in many cases, but it’s not very robust. First, it never closes files, which means it will fail one you need to load more than a few thousands file. Second, it assumes that you want all the data from each file and that it can all fit into memory. In many situations, you only need a small subset or an aggregated summary of the data from each file.
Here’s a slightly more sophisticated example of how to remedy these deficiencies:
def read_netcdfs(files, dim, transform_func=None):
def process_one_path(path):
# use a context manager, to ensure the file gets closed after use
with xr.open_dataset(path) as ds:
# transform_func should do some sort of selection or
# aggregation
if transform_func is not None:
ds = transform_func(ds)
# load all data from the transformed dataset, to ensure we can
# use it after closing each original file
ds.load()
return ds
paths = sorted(glob(files))
datasets = [process_one_path(p) for p in paths]
combined = xr.concat(datasets, dim)
return combined
# here we suppose we only care about the combined mean of each file;
# you might also use indexing operations like .sel to subset datasets
combined = read_netcdfs('/all/my/files/*.nc', dim='time',
transform_func=lambda ds: ds.mean())
This pattern works well and is very robust. We’ve used similar code to process tens of thousands of files constituting 100s of GB of data.
Writing encoded data¶
Conversely, you can customize how xarray writes netCDF files on disk by
providing explicit encodings for each dataset variable. The encoding
argument takes a dictionary with variable names as keys and variable specific
encodings as values. These encodings are saved as attributes on the netCDF
variables on disk, which allows xarray to faithfully read encoded data back into
memory.
It is important to note that using encodings is entirely optional: if you do not
supply any of these encoding options, xarray will write data to disk using a
default encoding, or the options in the encoding attribute, if set.
This works perfectly fine in most cases, but encoding can be useful for
additional control, especially for enabling compression.
In the file on disk, these encodings as saved as attributes on each variable, which allow xarray and other CF-compliant tools for working with netCDF files to correctly read the data.
Scaling and type conversions¶
These encoding options work on any version of the netCDF file format:
dtype: Any valid NumPy dtype or string convertable to a dtype, e.g.,'int16'or'float32'. This controls the type of the data written on disk._FillValue: Values ofNaNin xarray variables are remapped to this value when saved on disk. This is important when converting floating point with missing values to integers on disk, becauseNaNis not a valid value for integer dtypes. As a default, variables with float types are attributed a_FillValueofNaNin the output file, unless explicitly disabled with an encoding{'_FillValue': None}.scale_factorandadd_offset: Used to convert from encoded data on disk to to the decoded data in memory, according to the formuladecoded = scale_factor * encoded + add_offset.
These parameters can be fruitfully combined to compress discretized data on disk. For
example, to save the variable foo with a precision of 0.1 in 16-bit integers while
converting NaN to -9999, we would use
encoding={'foo': {'dtype': 'int16', 'scale_factor': 0.1, '_FillValue': -9999}}.
Compression and decompression with such discretization is extremely fast.
String encoding¶
xarray can write unicode strings to netCDF files in two ways:
As variable length strings. This is only supported on netCDF4 (HDF5) files.
By encoding strings into bytes, and writing encoded bytes as a character array. The default encoding is UTF-8.
By default, we use variable length strings for compatible files and fall-back
to using encoded character arrays. Character arrays can be selected even for
netCDF4 files by setting the dtype field in encoding to S1
(corresponding to NumPy’s single-character bytes dtype).
If character arrays are used:
The string encoding that was used is stored on disk in the
_Encodingattribute, which matches an ad-hoc convention adopted by the netCDF4-Python library. At the time of this writing (October 2017), a standard convention for indicating string encoding for character arrays in netCDF files was still under discussion. Technically, you can use any string encoding recognized by Python if you feel the need to deviate from UTF-8, by setting the_Encodingfield inencoding. But we don’t recommend it.The character dimension name can be specifed by the
char_dim_namefield of a variable’sencoding. If this is not specified the default name for the character dimension is'string%s' % data.shape[-1]. When decoding character arrays from existing files, thechar_dim_nameis added to the variablesencodingto preserve if encoding happens, but the field can be edited by the user.
Warning
Missing values in bytes or unicode string arrays (represented by NaN in
xarray) are currently written to disk as empty strings ''. This means
missing values will not be restored when data is loaded from disk.
This behavior is likely to change in the future (GH1647).
Unfortunately, explicitly setting a _FillValue for string arrays to handle
missing values doesn’t work yet either, though we also hope to fix this in the
future.
Chunk based compression¶
zlib, complevel, fletcher32, continguous and chunksizes
can be used for enabling netCDF4/HDF5’s chunk based compression, as described
in the documentation for createVariable for netCDF4-Python. This only works
for netCDF4 files and thus requires using format='netCDF4' and either
engine='netcdf4' or engine='h5netcdf'.
Chunk based gzip compression can yield impressive space savings, especially for sparse data, but it comes with significant performance overhead. HDF5 libraries can only read complete chunks back into memory, and maximum decompression speed is in the range of 50-100 MB/s. Worse, HDF5’s compression and decompression currently cannot be parallelized with dask. For these reasons, we recommend trying discretization based compression (described above) first.
Time units¶
The units and calendar attributes control how xarray serializes datetime64 and
timedelta64 arrays to datasets on disk as numeric values. The units encoding
should be a string like 'days since 1900-01-01' for datetime64 data or a string
like 'days' for timedelta64 data. calendar should be one of the calendar types
supported by netCDF4-python: ‘standard’, ‘gregorian’, ‘proleptic_gregorian’ ‘noleap’,
‘365_day’, ‘360_day’, ‘julian’, ‘all_leap’, ‘366_day’.
By default, xarray uses the 'proleptic_gregorian' calendar and units of the smallest time
difference between values, with a reference time of the first time value.
Coordinates¶
You can control the coordinates attribute written to disk by specifying DataArray.encoding["coordinates"].
If not specified, xarray automatically sets DataArray.encoding["coordinates"] to a space-delimited list
of names of coordinate variables that share dimensions with the DataArray being written.
This allows perfect roundtripping of xarray datasets but may not be desirable.
When an xarray Dataset contains non-dimensional coordinates that do not share dimensions with any of
the variables, these coordinate variable names are saved under a “global” "coordinates" attribute.
This is not CF-compliant but again facilitates roundtripping of xarray datasets.
Invalid netCDF files¶
The library h5netcdf allows writing some dtypes (booleans, complex, …) that aren’t
allowed in netCDF4 (see
h5netcdf documentation).
This feature is availabe through DataArray.to_netcdf() and
Dataset.to_netcdf() when used with engine="h5netcdf"
and currently raises a warning unless invalid_netcdf=True is set:
# Writing complex valued data
In [8]: da = xr.DataArray([1.0 + 1.0j, 2.0 + 2.0j, 3.0 + 3.0j])
In [9]: da.to_netcdf("complex.nc", engine="h5netcdf", invalid_netcdf=True)
# Reading it back
In [10]: xr.open_dataarray("complex.nc", engine="h5netcdf")
Out[10]:
<xarray.DataArray (dim_0: 3)>
array([1.+1.j, 2.+2.j, 3.+3.j])
Dimensions without coordinates: dim_0
Warning
Note that this produces a file that is likely to be not readable by other netCDF libraries!
Iris¶
The Iris tool allows easy reading of common meteorological and climate model formats
(including GRIB and UK MetOffice PP files) into Cube objects which are in many ways very
similar to DataArray objects, while enforcing a CF-compliant data model. If iris is
installed xarray can convert a DataArray into a Cube using
DataArray.to_iris():
In [11]: da = xr.DataArray(
....: np.random.rand(4, 5),
....: dims=["x", "y"],
....: coords=dict(x=[10, 20, 30, 40], y=pd.date_range("2000-01-01", periods=5)),
....: )
....:
In [12]: cube = da.to_iris()
In [13]: cube
Out[13]: <iris 'Cube' of unknown / (unknown) (x: 4; y: 5)>
Conversely, we can create a new DataArray object from a Cube using
DataArray.from_iris():
In [14]: da_cube = xr.DataArray.from_iris(cube)
In [15]: da_cube
Out[15]:
<xarray.DataArray (x: 4, y: 5)>
array([[0.8529 , 0.235507, 0.146227, 0.589869, 0.574012],
[0.06127 , 0.590426, 0.24535 , 0.340445, 0.984729],
[0.91954 , 0.037772, 0.861549, 0.753569, 0.405179],
[0.343526, 0.170917, 0.394659, 0.641666, 0.274592]])
Coordinates:
* x (x) int64 10 20 30 40
* y (y) datetime64[ns] 2000-01-01 2000-01-02 ... 2000-01-04 2000-01-05
OPeNDAP¶
xarray includes support for OPeNDAP (via the netCDF4 library or Pydap), which lets us access large datasets over HTTP.
For example, we can open a connection to GBs of weather data produced by the PRISM project, and hosted by IRI at Columbia:
In [16]: remote_data = xr.open_dataset(
....: "http://iridl.ldeo.columbia.edu/SOURCES/.OSU/.PRISM/.monthly/dods",
....: decode_times=False,
....: )
....:
In [17]: remote_data
Out[17]:
<xarray.Dataset>
Dimensions: (T: 1422, X: 1405, Y: 621)
Coordinates:
* X (X) float32 -125.0 -124.958 -124.917 -124.875 -124.833 -124.792 -124.75 ...
* T (T) float32 -779.5 -778.5 -777.5 -776.5 -775.5 -774.5 -773.5 -772.5 -771.5 ...
* Y (Y) float32 49.9167 49.875 49.8333 49.7917 49.75 49.7083 49.6667 49.625 ...
Data variables:
ppt (T, Y, X) float64 ...
tdmean (T, Y, X) float64 ...
tmax (T, Y, X) float64 ...
tmin (T, Y, X) float64 ...
Attributes:
Conventions: IRIDL
expires: 1375315200
Note
Like many real-world datasets, this dataset does not entirely follow
CF conventions. Unexpected formats will usually cause xarray’s automatic
decoding to fail. The way to work around this is to either set
decode_cf=False in open_dataset to turn off all use of CF
conventions, or by only disabling the troublesome parser.
In this case, we set decode_times=False because the time axis here
provides the calendar attribute in a format that xarray does not expect
(the integer 360 instead of a string like '360_day').
We can select and slice this data any number of times, and nothing is loaded over the network until we look at particular values:
In [18]: tmax = remote_data["tmax"][:500, ::3, ::3]
In [19]: tmax
Out[19]:
<xarray.DataArray 'tmax' (T: 500, Y: 207, X: 469)>
[48541500 values with dtype=float64]
Coordinates:
* Y (Y) float32 49.9167 49.7917 49.6667 49.5417 49.4167 49.2917 ...
* X (X) float32 -125.0 -124.875 -124.75 -124.625 -124.5 -124.375 ...
* T (T) float32 -779.5 -778.5 -777.5 -776.5 -775.5 -774.5 -773.5 ...
Attributes:
pointwidth: 120
standard_name: air_temperature
units: Celsius_scale
expires: 1443657600
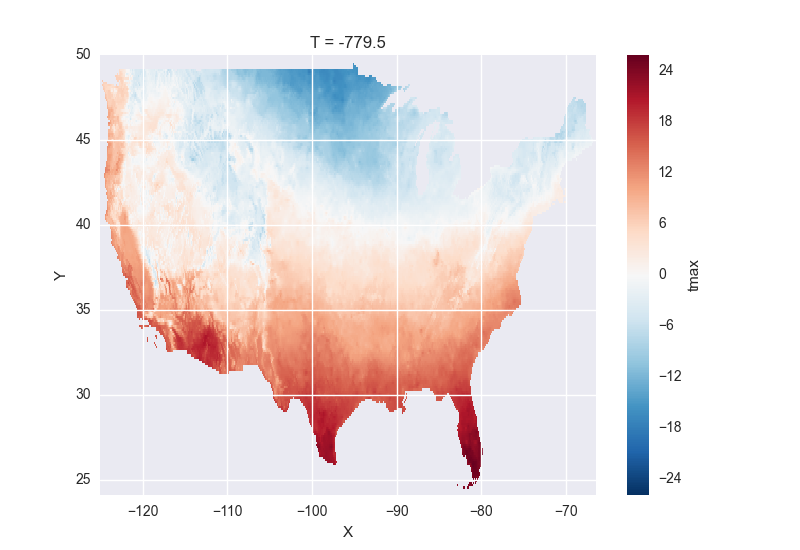
# the data is downloaded automatically when we make the plot
In [20]: tmax[0].plot()
Some servers require authentication before we can access the data. For this
purpose we can explicitly create a backends.PydapDataStore
and pass in a Requests session object. For example for
HTTP Basic authentication:
import xarray as xr
import requests
session = requests.Session()
session.auth = ('username', 'password')
store = xr.backends.PydapDataStore.open('http://example.com/data',
session=session)
ds = xr.open_dataset(store)
Pydap’s cas module has functions that generate custom sessions for servers that use CAS single sign-on. For example, to connect to servers that require NASA’s URS authentication:
import xarray as xr
from pydata.cas.urs import setup_session
ds_url = 'https://gpm1.gesdisc.eosdis.nasa.gov/opendap/hyrax/example.nc'
session = setup_session('username', 'password', check_url=ds_url)
store = xr.backends.PydapDataStore.open(ds_url, session=session)
ds = xr.open_dataset(store)
Pickle¶
The simplest way to serialize an xarray object is to use Python’s built-in pickle module:
In [21]: import pickle
# use the highest protocol (-1) because it is way faster than the default
# text based pickle format
In [22]: pkl = pickle.dumps(ds, protocol=-1)
In [23]: pickle.loads(pkl)
Out[23]:
<xarray.Dataset>
Dimensions: (x: 4, y: 5)
Coordinates:
* x (x) int64 10 20 30 40
* y (y) datetime64[ns] 2000-01-01 2000-01-02 ... 2000-01-04 2000-01-05
z (x) object ...
Data variables:
foo (x, y) float64 ...
Pickling is important because it doesn’t require any external libraries
and lets you use xarray objects with Python modules like
multiprocessing or Dask. However, pickling is
not recommended for long-term storage.
Restoring a pickle requires that the internal structure of the types for the pickled data remain unchanged. Because the internal design of xarray is still being refined, we make no guarantees (at this point) that objects pickled with this version of xarray will work in future versions.
Note
When pickling an object opened from a NetCDF file, the pickle file will
contain a reference to the file on disk. If you want to store the actual
array values, load it into memory first with Dataset.load()
or Dataset.compute().
Dictionary¶
We can convert a Dataset (or a DataArray) to a dict using
Dataset.to_dict():
In [24]: d = ds.to_dict()
In [25]: d
Out[25]:
{'coords': {'x': {'dims': ('x',), 'attrs': {}, 'data': [10, 20, 30, 40]},
'y': {'dims': ('y',),
'attrs': {},
'data': [datetime.datetime(2000, 1, 1, 0, 0),
datetime.datetime(2000, 1, 2, 0, 0),
datetime.datetime(2000, 1, 3, 0, 0),
datetime.datetime(2000, 1, 4, 0, 0),
datetime.datetime(2000, 1, 5, 0, 0)]},
'z': {'dims': ('x',), 'attrs': {}, 'data': ['a', 'b', 'c', 'd']}},
'attrs': {},
'dims': {'x': 4, 'y': 5},
'data_vars': {'foo': {'dims': ('x', 'y'),
'attrs': {},
'data': [[0.12696983303810094,
0.966717838482003,
0.26047600586578334,
0.8972365243645735,
0.37674971618967135],
[0.33622174433445307,
0.45137647047539964,
0.8402550832613813,
0.12310214428849964,
0.5430262020470384],
[0.37301222522143085,
0.4479968246859435,
0.12944067971751294,
0.8598787065799693,
0.8203883631195572],
[0.35205353914802473,
0.2288873043216132,
0.7767837505077176,
0.5947835894851238,
0.1375535565632705]]}}}
We can create a new xarray object from a dict using
Dataset.from_dict():
In [26]: ds_dict = xr.Dataset.from_dict(d)
In [27]: ds_dict
Out[27]:
<xarray.Dataset>
Dimensions: (x: 4, y: 5)
Coordinates:
* x (x) int64 10 20 30 40
* y (y) datetime64[ns] 2000-01-01 2000-01-02 ... 2000-01-04 2000-01-05
z (x) <U1 'a' 'b' 'c' 'd'
Data variables:
foo (x, y) float64 0.127 0.9667 0.2605 0.8972 ... 0.7768 0.5948 0.1376
Dictionary support allows for flexible use of xarray objects. It doesn’t require external libraries and dicts can easily be pickled, or converted to json, or geojson. All the values are converted to lists, so dicts might be quite large.
To export just the dataset schema, without the data itself, use the
data=False option:
In [28]: ds.to_dict(data=False)
Out[28]:
{'coords': {'x': {'dims': ('x',),
'attrs': {},
'dtype': 'int64',
'shape': (4,)},
'y': {'dims': ('y',), 'attrs': {}, 'dtype': 'datetime64[ns]', 'shape': (5,)},
'z': {'dims': ('x',), 'attrs': {}, 'dtype': 'object', 'shape': (4,)}},
'attrs': {},
'dims': {'x': 4, 'y': 5},
'data_vars': {'foo': {'dims': ('x', 'y'),
'attrs': {},
'dtype': 'float64',
'shape': (4, 5)}}}
This can be useful for generating indices of dataset contents to expose to search indices or other automated data discovery tools.
Rasterio¶
GeoTIFFs and other gridded raster datasets can be opened using rasterio, if
rasterio is installed. Here is an example of how to use
open_rasterio() to read one of rasterio’s test files:
In [29]: rio = xr.open_rasterio("RGB.byte.tif")
In [30]: rio
Out[30]:
<xarray.DataArray (band: 3, y: 718, x: 791)>
[1703814 values with dtype=uint8]
Coordinates:
* band (band) int64 1 2 3
* y (y) float64 2.827e+06 2.826e+06 2.826e+06 2.826e+06 2.826e+06 ...
* x (x) float64 1.021e+05 1.024e+05 1.027e+05 1.03e+05 1.033e+05 ...
Attributes:
res: (300.0379266750948, 300.041782729805)
transform: (300.0379266750948, 0.0, 101985.0, 0.0, -300.041782729805, 28...
is_tiled: 0
crs: +init=epsg:32618
The x and y coordinates are generated out of the file’s metadata
(bounds, width, height), and they can be understood as cartesian
coordinates defined in the file’s projection provided by the crs attribute.
crs is a PROJ4 string which can be parsed by e.g. pyproj or rasterio.
See Parsing rasterio geocoordinates
for an example of how to convert these to longitudes and latitudes.
Warning
This feature has been added in xarray v0.9.6 and should still be considered as being experimental. Please report any bug you may find on xarray’s github repository.
Additionally, you can use rioxarray for reading in GeoTiff, netCDF or other GDAL readable raster data using rasterio as well as for exporting to a geoTIFF. rioxarray can also handle geospatial related tasks such as re-projecting and clipping.
In [31]: import rioxarray
In [32]: rds = rioxarray.open_rasterio("RGB.byte.tif")
In [33]: rds
Out[33]:
<xarray.DataArray (band: 3, y: 718, x: 791)>
[1703814 values with dtype=uint8]
Coordinates:
* band (band) int64 1 2 3
* y (y) float64 2.827e+06 2.826e+06 ... 2.612e+06 2.612e+06
* x (x) float64 1.021e+05 1.024e+05 ... 3.389e+05 3.392e+05
spatial_ref int64 0
Attributes:
STATISTICS_MAXIMUM: 255
STATISTICS_MEAN: 29.947726688477
STATISTICS_MINIMUM: 0
STATISTICS_STDDEV: 52.340921626611
transform: (300.0379266750948, 0.0, 101985.0, 0.0, -300.0417827...
_FillValue: 0.0
scale_factor: 1.0
add_offset: 0.0
grid_mapping: spatial_ref
In [34]: rds.rio.crs
Out[34]: CRS.from_epsg(32618)
In [35]: rds4326 = rds.rio.reproject("epsg:4326")
In [36]: rds4326.rio.crs
Out[36]: CRS.from_epsg(4326)
In [37]: rds4326.rio.to_raster("RGB.byte.4326.tif")
Zarr¶
Zarr is a Python package providing an implementation of chunked, compressed, N-dimensional arrays. Zarr has the ability to store arrays in a range of ways, including in memory, in files, and in cloud-based object storage such as Amazon S3 and Google Cloud Storage. Xarray’s Zarr backend allows xarray to leverage these capabilities.
Warning
Zarr support is still an experimental feature. Please report any bugs or unexepected behavior via github issues.
Xarray can’t open just any zarr dataset, because xarray requires special metadata (attributes) describing the dataset dimensions and coordinates. At this time, xarray can only open zarr datasets that have been written by xarray. For implementation details, see Zarr Encoding Specification.
To write a dataset with zarr, we use the Dataset.to_zarr method.
To write to a local directory, we pass a path to a directory
In [38]: ds = xr.Dataset(
....: {"foo": (("x", "y"), np.random.rand(4, 5))},
....: coords={
....: "x": [10, 20, 30, 40],
....: "y": pd.date_range("2000-01-01", periods=5),
....: "z": ("x", list("abcd")),
....: },
....: )
....:
In [39]: ds.to_zarr("path/to/directory.zarr")
Out[39]: <xarray.backends.zarr.ZarrStore at 0x7f90537c0ea0>
(The suffix .zarr is optional–just a reminder that a zarr store lives
there.) If the directory does not exist, it will be created. If a zarr
store is already present at that path, an error will be raised, preventing it
from being overwritten. To override this behavior and overwrite an existing
store, add mode='w' when invoking to_zarr.
It is also possible to append to an existing store. For that, set
append_dim to the name of the dimension along which to append. mode
can be omitted as it will internally be set to 'a'.
In [40]: ds1 = xr.Dataset(
....: {"foo": (("x", "y", "t"), np.random.rand(4, 5, 2))},
....: coords={
....: "x": [10, 20, 30, 40],
....: "y": [1, 2, 3, 4, 5],
....: "t": pd.date_range("2001-01-01", periods=2),
....: },
....: )
....:
In [41]: ds1.to_zarr("path/to/directory.zarr")
Out[41]: <xarray.backends.zarr.ZarrStore at 0x7f90537c7310>
In [42]: ds2 = xr.Dataset(
....: {"foo": (("x", "y", "t"), np.random.rand(4, 5, 2))},
....: coords={
....: "x": [10, 20, 30, 40],
....: "y": [1, 2, 3, 4, 5],
....: "t": pd.date_range("2001-01-03", periods=2),
....: },
....: )
....:
In [43]: ds2.to_zarr("path/to/directory.zarr", append_dim="t")
Out[43]: <xarray.backends.zarr.ZarrStore at 0x7f90537c72c0>
To store variable length strings use dtype=object.
To read back a zarr dataset that has been created this way, we use the
open_zarr() method:
In [44]: ds_zarr = xr.open_zarr("path/to/directory.zarr")
In [45]: ds_zarr
Out[45]:
<xarray.Dataset>
Dimensions: (t: 4, x: 4, y: 5)
Coordinates:
* t (t) datetime64[ns] 2001-01-01 2001-01-02 2001-01-03 2001-01-04
* x (x) int64 10 20 30 40
* y (y) int64 1 2 3 4 5
Data variables:
foo (x, y, t) float64 dask.array<chunksize=(4, 5, 2), meta=np.ndarray>
Cloud Storage Buckets¶
It is possible to read and write xarray datasets directly from / to cloud
storage buckets using zarr. This example uses the gcsfs package to provide
a MutableMapping interface to Google Cloud Storage, which we can then
pass to xarray:
import gcsfs
fs = gcsfs.GCSFileSystem(project='<project-name>', token=None)
gcsmap = gcsfs.mapping.GCSMap('<bucket-name>', gcs=fs, check=True, create=False)
# write to the bucket
ds.to_zarr(store=gcsmap)
# read it back
ds_gcs = xr.open_zarr(gcsmap)
Zarr Compressors and Filters¶
There are many different options for compression and filtering possible with
zarr. These are described in the
zarr documentation.
These options can be passed to the to_zarr method as variable encoding.
For example:
In [46]: import zarr
In [47]: compressor = zarr.Blosc(cname="zstd", clevel=3, shuffle=2)
In [48]: ds.to_zarr("foo.zarr", encoding={"foo": {"compressor": compressor}})
Out[48]: <xarray.backends.zarr.ZarrStore at 0x7f905335ee50>
Note
Not all native zarr compression and filtering options have been tested with xarray.
Consolidated Metadata¶
Xarray needs to read all of the zarr metadata when it opens a dataset.
In some storage mediums, such as with cloud object storage (e.g. amazon S3),
this can introduce significant overhead, because two separate HTTP calls to the
object store must be made for each variable in the dataset.
With version 2.3, zarr will support a feature called consolidated metadata,
which allows all metadata for the entire dataset to be stored with a single
key (by default called .zmetadata). This can drastically speed up
opening the store. (For more information on this feature, consult the
zarr docs.)
If you have zarr version 2.3 or greater, xarray can write and read stores
with consolidated metadata. To write consolidated metadata, pass the
consolidated=True option to the
Dataset.to_zarr method:
ds.to_zarr('foo.zarr', consolidated=True)
To read a consolidated store, pass the consolidated=True option to
open_zarr():
ds = xr.open_zarr('foo.zarr', consolidated=True)
Xarray can’t perform consolidation on pre-existing zarr datasets. This should be done directly from zarr, as described in the zarr docs.
GRIB format via cfgrib¶
xarray supports reading GRIB files via ECMWF cfgrib python driver,
if it is installed. To open a GRIB file supply engine='cfgrib'
to open_dataset():
In [49]: ds_grib = xr.open_dataset("example.grib", engine="cfgrib")
We recommend installing cfgrib via conda:
conda install -c conda-forge cfgrib
Formats supported by PyNIO¶
xarray can also read GRIB, HDF4 and other file formats supported by PyNIO,
if PyNIO is installed. To use PyNIO to read such files, supply
engine='pynio' to open_dataset().
We recommend installing PyNIO via conda:
conda install -c conda-forge pynio
Formats supported by PseudoNetCDF¶
xarray can also read CAMx, BPCH, ARL PACKED BIT, and many other file formats supported by PseudoNetCDF, if PseudoNetCDF is installed. PseudoNetCDF can also provide Climate Forecasting Conventions to CMAQ files. In addition, PseudoNetCDF can automatically register custom readers that subclass PseudoNetCDF.PseudoNetCDFFile. PseudoNetCDF can identify readers heuristically, or format can be specified via a key in backend_kwargs.
To use PseudoNetCDF to read such files, supply
engine='pseudonetcdf' to open_dataset().
Add backend_kwargs={'format': '<format name>'} where <format name>
options are listed on the PseudoNetCDF page.
CSV and other formats supported by Pandas¶
For more options (tabular formats and CSV files in particular), consider exporting your objects to pandas and using its broad range of IO tools. For CSV files, one might also consider xarray_extras.